迁移-批处理操作
同区域跨账号
技术难度等级与先决知识
Section titled “技术难度等级与先决知识”- 技术难度:中高级
- 所需知识:
- 熟悉 AWS S3 存储桶策略与 IAM 角色配置
- 理解 S3 跨账户访问模型
- 掌握 S3 Inventory 功能及其输出格式
- 能够通过 AWS Management Console 创建和管理资源
- 了解对象元数据、ETag 及校验机制基本概念
| 资源类型 | 桶名称 | 账户归属 | 说明 |
|---|---|---|---|
| 源存储桶 | r75se4ex2wl1-source | 账户 A | 包含待迁移对象 |
| 目标存储桶 | r75se4ex2wl1-destination | 账户 B | 接收迁移对象 |
| S3 库存清单 | r75se4ex2wl1-inventory | 账户 A | 自动生成的对象列表(CSV、Json 或 Parquet 格式) |
| 报告存储桶 | 账户 A(推荐) | 存放批处理作业执行报告 | |
| IAM 执行角色 | S3BatchCopyRole | 账户 A | S3 Batch Operations 使用的角色 |
| IAM 执行角色策略 | S3BatchCopyPolicy | 账户A | 所有涉及复制资源的授权 |
| S3 批处理 作业 | 账户 A | 在控制台创建并提交 |
注:所有操作在 AWS Management Console 中完成。
关键概念说明
Section titled “关键概念说明”- S3 库存:每日或每小时生成的源桶对象清单,包含 key、size、ETag、storage class 等字段,可直接用作 批处理操作 的 manifest。
- Manifest:批处理 作业的输入文件。使用 S3 Inventory 时,需选择
S3InventoryReport_CSV_20211130或S3InventoryReport_Parquet格式。 - 执行角色:必须具备读取源桶、写入目标桶(逻辑声明)、写入报告桶的权限。
- 跨账户写入授权:由账户 B 在其目标桶上通过存储桶策略显式授予账户 A 的执行角色写入权限。
步骤 1:在账户 A 中启用并配置 S3 库存配置(用于生成清单)
Section titled “步骤 1:在账户 A 中启用并配置 S3 库存配置(用于生成清单)”- 登录 账户 A 的 AWS 控制台,进入 S3 > 源存储桶 > 管理 > 库存配置
- 点击 创建库存配置
- 配置如下:
- 库存名称:
batch-copy-inventory - 报告存储桶:此桶用来存储统计后的清单,如
r75se4ex2wl1-inventory。- 复制给出的存储桶权限(下面)进行授权
- 频率:每天 或 每周(根据数据更新频率选择)
- 文件格式:选择 CSV(批处理操作 支持 CSV 和 Parquet,CSV 更易调试)
- 清单加密:不指定加密密钥
- 其他元数据字段:可选
大小,最后修改时间,ETag
- 库存名称:
- 保存配置
清单存储桶权限
编辑r75se4ex2wl1-inventory存储桶策略->添加语句->替换掉灰色的部分。
⏳ 首次清单通常在 24-48 小时内生成,路径形如:
s3://r75se4ex2wl1-inventory/r75se4ex2wl1-source/batch-copy-inventory/2025-12-22T01-00Z/manifest.json
步骤 2:在账户 A 中创建 IAM 执行角色
Section titled “步骤 2:在账户 A 中创建 IAM 执行角色”- 进入 IAM > 角色 > 创建角色
- 可信实体类型:选择 AWS 服务
- 使用案例:选择 S3 -> S3 Batch Operations
- 点击 下一步
- 设置角色名称(例如
S3BatchCopyRole),完成创建 - 添加权限策略(创建内联策略):
- 策略名称:
S3BatchCopyPolicy
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:GetObject", "s3:GetObjectVersion" ], "Resource": "arn:aws:s3:::r75se4ex2wl1-inventory/*" }, { "Effect": "Allow", "Action": [ "s3:GetObject", "s3:GetObjectVersion", "s3:GetObjectAcl", "s3:GetObjectVersionAcl", "s3:GetObjectTagging", "s3:GetObjectVersionTagging", "s3express:CreateSession" ], "Resource": [ "arn:aws:s3:::r75se4ex2wl1-source", "arn:aws:s3:::r75se4ex2wl1-source/*" ] }, { "Effect": "Allow", "Action": [ "s3:PutObject", "s3:PutObjectAcl", "s3:PutObjectTagging", "s3:PutObjectLegalHold", "s3:PutObjectRetention", "s3express:CreateSession", "s3:GetBucketObjectLockConfiguration" ], "Resource": [ "arn:aws:s3:::r75se4ex2wl1-destination", "arn:aws:s3:::r75se4ex2wl1-destination/*" ] }, { "Effect": "Allow", "Action": [ "s3:PutObject", "s3:PutObjectAcl", "s3:PutObjectTagging", "s3:PutObjectLegalHold", "s3:PutObjectRetention", "s3express:CreateSession", "s3:GetBucketObjectLockConfiguration" ], "Resource": [ "arn:aws:s3:::r75se4ex2wl1-result", "arn:aws:s3:::r75se4ex2wl1-result/*" ] }, { "Action": [ "kms:Decrypt", "kms:GenerateDataKey" ], "Effect": "Allow", "Condition": { "StringLike": { "kms:ViaService": "s3.ap-southeast-5.amazonaws.com", "kms:EncryptionContext:aws:s3:arn": [ "arn:aws:s3:::r75se4ex2wl1-destination", "arn:aws:s3:::r75se4ex2wl1-result", "arn:aws:s3:::r75se4ex2wl1-destination/*", "arn:aws:s3:::r75se4ex2wl1-result/*" ] } }, "Resource": "*" }, { "Effect": "Allow", "Action": [ "s3:PutObject" ], "Resource": "arn:aws:s3:::r75se4ex2wl1-result/*" } ]}注意:即使目标桶属于账户 B,此处仍需在策略中声明其 ARN,否则作业创建会失败。
步骤 3:在账户 B 中为目标存储桶配置存储桶策略
Section titled “步骤 3:在账户 B 中为目标存储桶配置存储桶策略”- 登录 账户 B 的 AWS 控制台,进入 S3 > 目标存储桶 > 权限 > 桶策略
- 添加以下策略(替换占位符):
{ "Version": "2012-10-17", "Statement": [ { "Sid": "AllowBatchOperationsDestinationObjectCOPY", "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::账户A ID:role/S3BatchCopyRole" }, "Action": [ "s3:PutObject", "s3:PutObjectVersionAcl", "s3:PutObjectAcl", "s3:PutObjectVersionTagging", "s3:PutObjectTagging", "s3:GetObject", "s3:GetObjectVersion", "s3:GetObjectAcl", "s3:GetObjectTagging", "s3:GetObjectVersionAcl", "s3:GetObjectVersionTagging" ], "Resource": "arn:aws:s3:::r75se4ex2wl1-destination/*" }, { "Sid": "AllowSourceAccountWrite", "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::账户A ID:root" }, "Action": [ "s3:PutObject", "s3:PutObjectAcl" ], "Resource": "arn:aws:s3:::r75se4ex2wl1-destination/*" } ]}- 对象所有权-> ACL已启用
- 对象所有权-> 存储桶拥有者优先
步骤 4:在账户 A 中为报告存储桶配置策略
Section titled “步骤 4:在账户 A 中为报告存储桶配置策略”- 进入 账户 A 的 S3 控制台,选择用于存放报告的存储桶(例如
r75se4ex2wl1-result) - 在 权限 > 桶策略 中添加:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "batchoperations.s3.amazonaws.com" }, "Action": "s3:*", "Resource": "arn:aws:s3:::r75se4ex2wl1-result/*", "Condition": { "StringEquals": { "aws:SourceAccount": "账户A ID" } } } ]}此策略确保仅账户 A 的 Batch 作业可写入报告。
步骤 5:在 AWS 控制台创建 S3 批处理操作 作业
Section titled “步骤 5:在 AWS 控制台创建 S3 批处理操作 作业”- 登录 账户 A,进入 S3 > 批处理操作 > 创建作业
- 范围:
- 对象列表:使用现有清单
- 清单格式:S3报告清单(manifest.json)
s3://r75se4ex2wl1-inventory/r75se4ex2wl1-source/batch-copy-inventory/2025-12-22T01-00Z/manifest.json
- 操作:复制
- 复制目标:填写目标桶
s3://r75se4ex2wl1-destination- 复制设置:选择系统默认配置或者指定设置;如果选择指定设置,则保持ACL默认配置
- 完成报告的存储桶:
s3://r75se4ex2wl1-result - IAM角色:
S3BatchCopyRole - 确认无误后,提交。
- 系统会对任务进行检查,无误之后,选择任务,点击运行作业,启动复制。
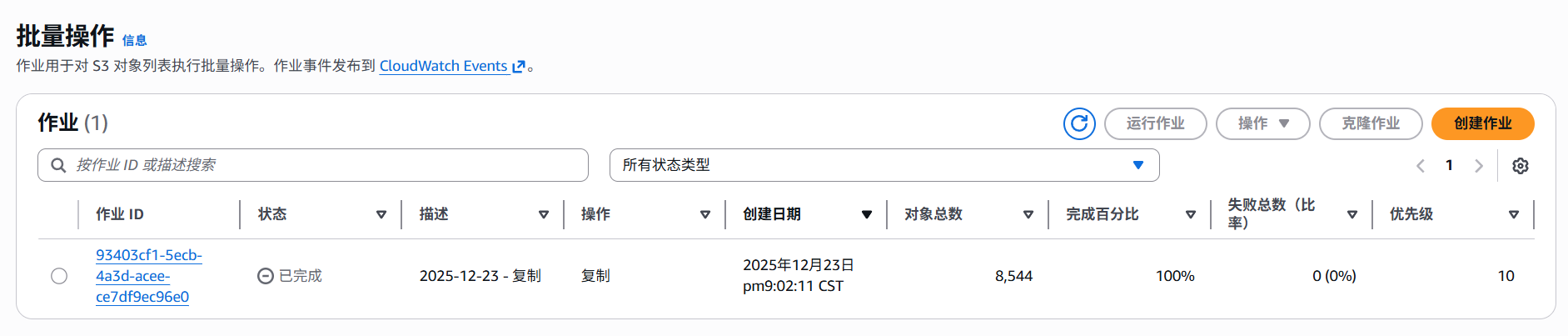
控制台会自动校验清单 ETag 和格式,避免手动错误。
- 作业以完成,但有错误
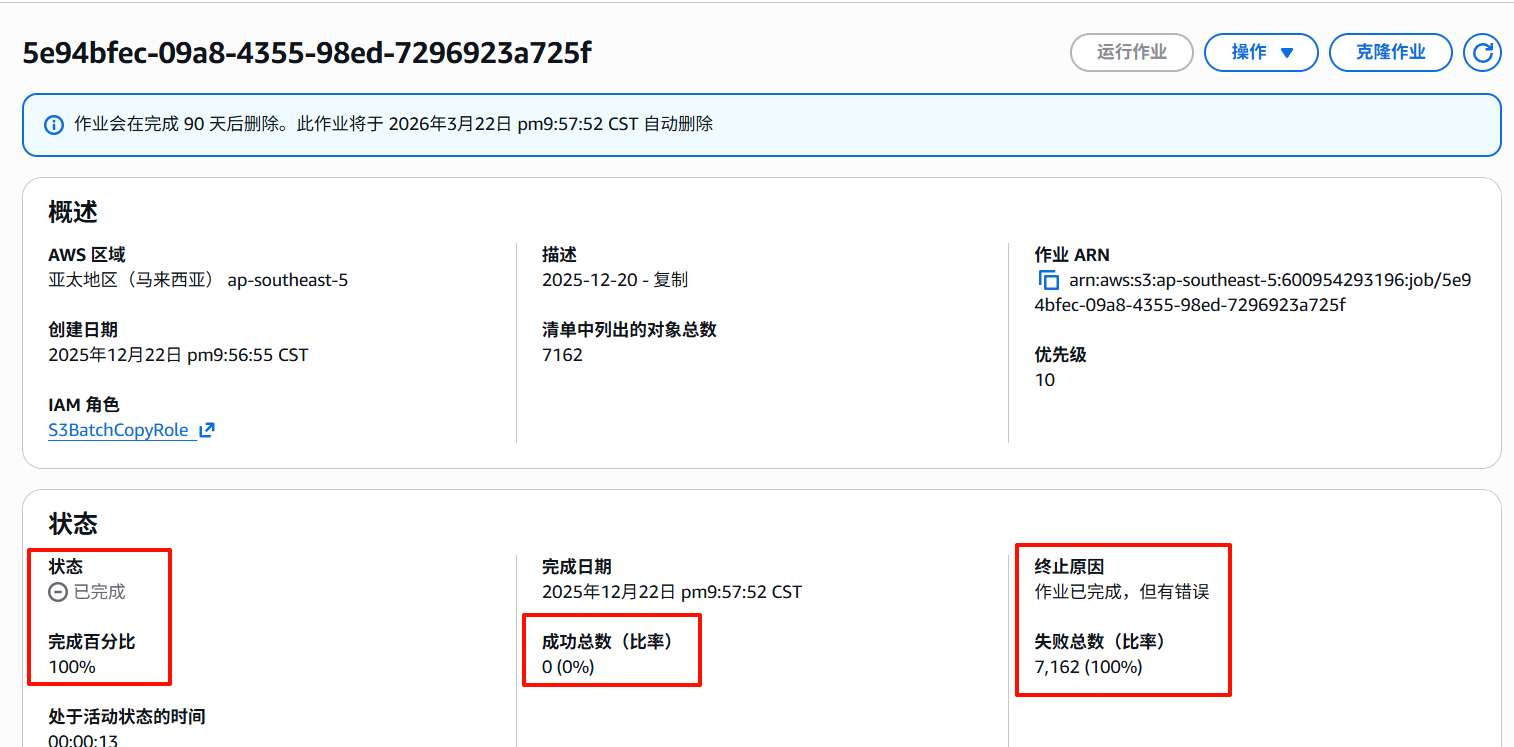
检查报告桶的任务编号目录中的result/xxx.csv文件中的错误代码
数据完整性验证方法
Section titled “数据完整性验证方法”任务完成后,必须验证数据是否完整、一致。建议采用以下方法:
方法 1:比对对象数量与大小
Section titled “方法 1:比对对象数量与大小”- 从 S3 库存配置 获取源桶对象总数与总大小(使用 Athena 或下载 CSV 统计)
- 在账户 B 的目标桶上启用 S3 Storage Lens 或运行 S3 Inventory,获取目标对象统计
- 对比两者数量与总字节数是否一致
方法 2:校验关键对象的 ETag
Section titled “方法 2:校验关键对象的 ETag”- 对于未加密或使用 SSE-S3 加密的对象,ETag = MD5 哈希值
- 从源桶 Inventory 清单中提取部分对象的
ETag - 在目标桶中使用 S3 控制台或 HeadObject API 获取对应对象的 ETag
- 比对是否一致
注意:若对象使用 SSE-KMS 或为 multipart upload,ETag 不等于 MD5,但 批处理操作 保证内容一致,ETag 差异属正常现象。
方法 3:分析作业报告
Section titled “方法 3:分析作业报告”- 下载复制报告
s3://r75se4ex2wl1-result/job-93403cf1-5ecb-4a3d-acee-ce7df9ec96e0/results/a878ed37f6c8b6644cfbfb60986e778155d96392.csv - 检查:
ResultCode是否为SucceededErrorCode/ErrorMessage是否为空- 失败任务数量是否为 0
报告包含每个对象的处理结果,是权威验证依据。
架构师审查要点(更新)
Section titled “架构师审查要点(更新)”- 清单可靠性:S3 库存配置 由 AWS 托管生成,比手动生成 CSV 更可靠,避免遗漏或格式错误。
- 无 CLI 依赖:全流程通过控制台完成,降低运维门槛,适合合规或审计环境。
- 可验证性:通过 库存配置 + 作业报告 + ETag 三重验证,确保迁移可信。
- 权限闭环:账户 B 仅开放最小必要权限,账户 A 角色权限明确,符合零信任原则。